- About
- Solutions
- Essentials
- Utilities
- Publications
- Product Delivery
- Support

The HPE Shadowbase A/A replication solution synchronizes databases by automatically replicating changes made to each database copy to all other copies in the application network.

Shadowbase Active/Active Data Replication at a Glance

Shadowbase technology contains a powerful database replication engine that provides bi- or multi-directional replication between the database copies and guarantees that all copies remain in a consistent and correct state. Therefore, each database copy is always in a consistent state and reflects the current state of the application.
Provided that the nodes and database copies are geographically distributed, A/A systems provide disaster tolerance for little or no additional cost when compared with active/passive (A/P) configurations. If a disaster takes out a node or a database copy, there are others in the network immediately available to take their place. In the most general case, the nodes are completely symmetric. Any transaction can be routed within the application network to any node which can read or update any set of data items in the database. This approach provides the most flexibility and maximizes system investment as requests can be load-balanced across all available processing capacity. If a node fails, users at the other nodes are unaffected. Also, the users at the failed node can be quickly switched to surviving nodes, thus restoring their services in seconds or less.
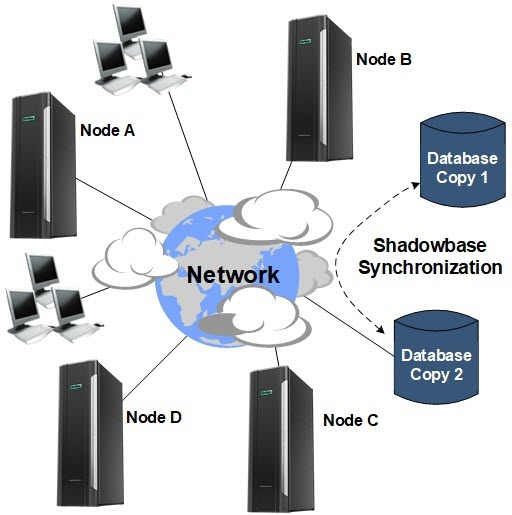
Figure 1 — An HPE Shadowbase Active/Active Architecture
As shown in Figure 1, an A/A system is a network of independent processing nodes, each having access to a common replicated database, so that all nodes can participate in a common application. Shadowbase replication keeps the data in the separate databases synchronized, and ensures that the records are accurate and up-to-date.
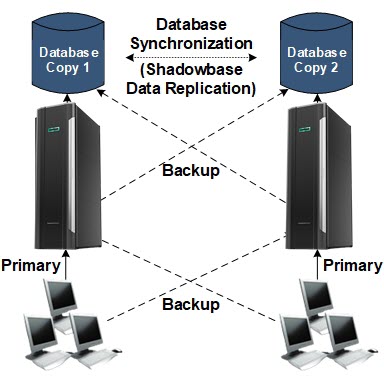
Figure 2 — How an HPE Shadowbase Active/Active System Works
As shown in Figure 2, the users are partitioned across the system’s network, with half on one node, and half on the other. If a node fails, users at that node can be immediately switched to another operable node. If a database fails, there is another consistent copy in the network that can be used. If a network component fails, alternate routes are provided. Using technology available today, failure recovery can be achieved in seconds or less. In short, let it fail (because it likely will), but fix it fast.

A concern that must be addressed in A/A database synchronization is that of data collisions. A data collision occurs when two nodes make a change to the same row in their database copy at substantially the same time. Each will replicate its change to the other database copy, thus overwriting the change made there. As a result, the database copies are different and both are wrong. HPE Shadowbase software can detect collisions and automatically resolve them in many cases. For those cases where Shadowbase replication cannot automatically resolve a collision, it supports embedding customer business logic into the replication engine to take whatever action is necessary to resolve the collision. There are also techniques to avoid data collisions in the first place, by application or data partitioning for example.
 Copy link to clipboard
Copy link to clipboard Email link
Email link Print
Print

