- About
- Solutions
- Essentials
- Utilities
- Publications
- Product Delivery
- Support

HPE Shadowbase A/P uni-directional replication is used for classic disaster recovery configurations. It supports applications that must be highly available but where some small data loss is tolerable. Customer relationship management (CRM) and human resources (HR) corporate applications are examples of this class of application, as are ATM transactions, which have a low value. If the ATM machine is down, the customer can go to a different ATM machine serviced by a different bank.

An HPE Shadowbase asynchronous uni-directional A/P system has a Recovery Point Objective (RPO) of greater than zero (it depends upon the replication latency of the data replication channel).
If Shadowbase synchronous replication is used, no data is lost following a source node failure, and an RPO of zero is achieved. The Recovery Time Objective (RTO) of an A/P system is measured in minutes or longer as applications are started following a failure of the active node, the databases are mounted, and the network is reconfigured.
Additional recovery time is typically required for the management decision time to failover to the backup system and for testing to ensure that the backup is performing properly.
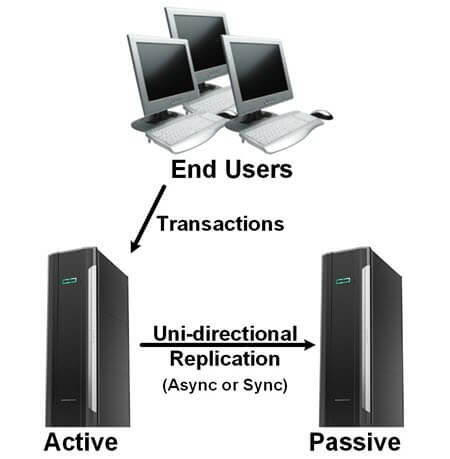
Figure 1 – Active/Passive Replication Architecture
Figure 1 shows clients posting transactions to an active system, with either Shadowbase synchronous or asynchronous uni-directional data replication keeping the passive, standby, disaster recovery system up-to-date.
 Copy link to clipboard
Copy link to clipboard Email link
Email link Print
Print
