- About
- Solutions
- Essentials
- Utilities
- Publications
- Product Delivery
- Support
Typically, early business applications had their own databases that supported their functions, which became siloed because no other systems had access to them. These islands of information proliferated as more and more departments were automated. Mergers and acquisitions compounded the problem since the companies integrated totally different systems, many of which were doing the same functional jobs.
Businesses soon recognized the analytical value of the data that they had available in their many islands of information. In fact, as businesses automated more systems, more data became available. Collecting this data for analysis was a challenge due to the incompatibilities between systems because there was no simple way (and often no way) for these systems to interact. An infrastructure was needed for data exchange, collection, and analysis that could provide a unified view of an enterprise’s data, so the data warehouse evolved to fill this need.
![]() White Paper: The Evolution of Real-Time Business Intelligence
White Paper: The Evolution of Real-Time Business Intelligence
Figure 1 depicts the online data warehouse concept: a single system for the repository of all of an organization’s data. Gift registry, sales promotions, inventory, and point-of-sale applications feed data into the data warehouse via ETL (extract, transform, and load) batch transfers. Knowledge workers and management have a dashboard for pertinent information, and can run ad-hoc queries on the data warehouse, generating meaningful reports for strategic decision-making.
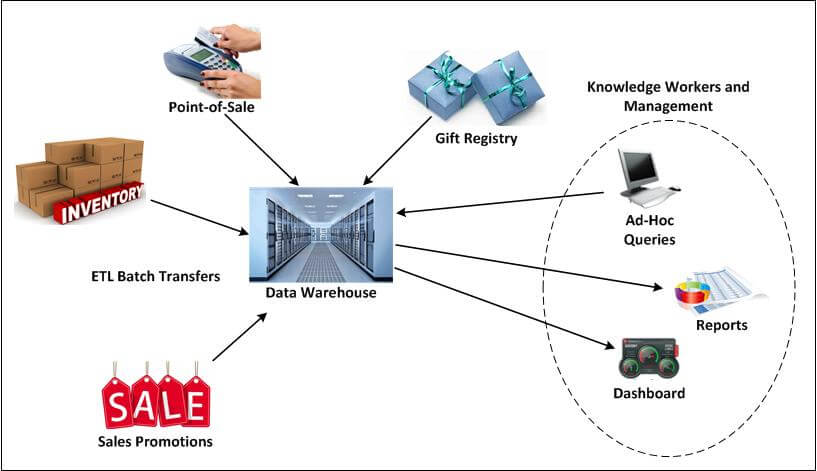
Figure 1 — The Data Warehouse
However, meeting the goal of a single repository for all of an organization’s data presents several very significant challenges:
To meet these needs, a broad range of powerful tools were developed over the years and became productized. They included:
![]() Use Case: Create the Ultimate Online Shopping Experience with Real-Time Business Intelligence
Use Case: Create the Ultimate Online Shopping Experience with Real-Time Business Intelligence
Early on, the one common interface that was provided between the disparate systems in an organization was magnetic tape. Tape formats were standardized, and any system could write tapes that could be read by other systems, and so the first data warehouses were fed by magnetic tapes prepared by the various systems within the organization. However, that left the problem of data disparity, since the data written by the different systems reflected their native data organizations. The data written to tape by one system often bore little relation to similar data written by another system.
Even more important was that the data warehouse’s database was designed to support the analytical functions required for the business intelligence and business insight function. This database design was typically a highly structured database with complex indices to support online analytical processing (OLAP), e.g., in an OLAP cube. Databases configured for OLAP allowed complex analytical and ad hoc queries with rapid execution time. The data fed to the data warehouse from the enterprise systems was converted to a format meaningful to the data warehouse. To solve the problem of initially loading this data into a data warehouse, keeping it updated, and resolving discrepancies, ETL utilities were developed.
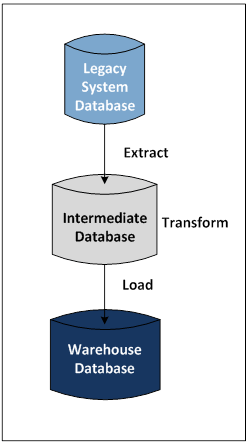
Figure 2 — Extract, Transform, Load (ETL)
Figure 2 shows the general flow of information (represented by the arrows) into a data warehouse using ETL utilities. First, the data from a legacy system database is extracted and placed in an intermediate database. The data is then transformed into a common data warehouse format and properly loaded into the warehouse database. This process solves the problem of data format disparity between systems.
As their names imply, these utilities extract data from source databases (in this case, a legacy system database), transform them into the common data warehouse format (the intermediate database), and load them into the warehouse database, as shown in Figure 2. The transform function is key to the success of this approach. It applies a series of rules to extracted data so that the data is properly formatted for loading into the data warehouse. Examples of transformation rules include:
The ETL function allows the consolidation of multiple data sources into a well-structured database that is used for complex analyses. The ETL process is executed periodically, such as daily, weekly, or monthly, depending upon the business needs. This process is called offline ETL because the target (warehouse) database is not continuously updated; it is updated on a periodic batch basis.
Though offline ETL serves its purpose well, it has some serious drawbacks. First, the data in the data warehouse is stale and could be days or weeks old, making it useful for strategic functions but not particularly adaptable to tactical uses. Second, the source database typically must be quiesced during the extract process; otherwise, the target database is in an inconsistent state following the load. As a result, the applications must be shut down, often for hours, resulting in loss of business services to customers.
In order to evolve to support real-time business intelligence, and derive business insight from data insight, the ETL function must be continuous and noninvasive. This function is online ETL, which is described later. In contrast to offline ETL, which provides stale but consistent responses to queries, online ETL provides current but varying responses to successive queries since the data that it is using is continually being updated to reflect the current state of the enterprise.
Offline ETL technology has served businesses for decades and the intelligence that is derived from this data informs long-term reactive strategic decision-making. However, short-term operational and proactive tactical decision-making continues to rely on intuition, and the business service outage associated with offline ETL is unacceptable in today’s 24-hour global economy.
The ETL utilities make data collection from many diverse systems practical. However, the captured data needs to be converted into information and knowledge in order to be useful.
Powerful data-mining engines were developed to support complex analyses and ad hoc queries on a data warehouse’s database. Data mining looks for patterns among hundreds of seemingly unrelated fields in a large database, patterns that identify previously unknown trends. These trends play a critical role in strategic decision-making because they reveal areas for process improvement and business opportunity. Examples of data-mining engines are those from SPSS (IBM) and Oracle. Facilities such as these are the foundation for online analytical processing (OLAP) systems.
Figure 3 shows a sample digital dashboard, a data reporting tool used by business managers to provide insight into their data using graphics and easily extractable information. The user sees a high-level view of a business process (or in this example, stock trading data), which can be drilled-down for specific and detailed statistics.
Figure 3 — Sample Digital Dashboard
Figure 4 shows a sample digital dashboard, a data reporting tool used by business managers to provide insight into their data using graphics and easily extractable information. The dashboard can provide insight into key performance indicators with colored lights, alerts, drill-downs, and gauges.
Figure 4 — Sample Reporting Tool
A digital dashboard provides the user a graphical high-level view of business processes that can be drilled-down to see more detail on a particular business process. This level of detail is often buried deep in the enterprise’s data, making it otherwise concealed to a business manager. For instance, with the digital dashboard shown in Figure 3, a knowledge worker clicking on an object will see the detailed statistics for that object.
Today, many versions of digital dashboards are available from a variety of software vendors. These dashboards and other sophisticated reporting tools are the collective product of business intelligence, data insight, and business insight systems. Driven by information discovered by a data-mining engine, they give the business manager the information required to:
As corporate-wide data warehouses came into use, it became clear in many cases that a full-blown data warehouse was overkill for many applications. Data marts evolved to solve this problem and are a specialized version of a data warehouse. Whereas a data warehouse is a single organizational repository of enterprise-wide data across all subject areas, a data mart is a subject-oriented repository of data designed to answer specific questions for a specific set of users. A data mart holds just a subset of the data that a data warehouse holds.
A data mart includes all of the needs of a data warehouse – ETL, data mining, and reporting. Since a data mart deals with only a subset of data, it is much smaller and more cost-effective than a full-scale data warehouse. In addition, because its database is much smaller because it only needs to hold subject-oriented data rather than all of the enterprise’s data, it is much more responsive to ad hoc queries and other analyses.
Data marts have become popular not only because they are less costly and more responsive but also because they are under the control of a department or division within the enterprise. Managers have their own local sources for information and knowledge rather than having to depend on a remote organization controlling the enterprise data warehouse.
 Copy link to clipboard
Copy link to clipboard Email link
Email link Print
Print