- About
- Solutions
- Essentials
- Utilities
- Publications
- Product Delivery
- Support
As online data warehouse technology matured, another solution for integrating enterprise-wide data appeared, called enterprise application integration (EAI). In many cases, the functioning of one enterprise system is significantly enhanced if it requests data or immediately receives newly generated data from other systems. For instance, an inventory-control system could be much more responsive if it has immediate access to point-of-sale data so that it could monitor product movement with real-time sales analysis. A bank could authorize a loan to a customer while the customer is sitting with the loan officer by analyzing in real-time the customer’s current business with the bank, his credit worthiness, and the current equity in his assets.
This capability requires that various legacy enterprise systems with different hardware, operating systems, and databases be enhanced so that they can talk to each other and exchange information in real-time or near real-time. The deployment of new business services, which were previously impossible, are enabled because the data and the applications that understood it are isolated from one another.
![]() White Paper: The Evolution of Real-Time Business Intelligence
White Paper: The Evolution of Real-Time Business Intelligence
EAI provides a means for linking such systems, in some cases without having to make sweeping changes to existing applications or data structures. In effect, whenever an event occurs in an application, it is sent via a publish/subscribe (or perhaps broadcast) mechanism to other applications in other systems that may be interested in this event. Likewise, one system requests data from another system in real-time via a request/response mechanism. There are two techniques for implementing EAI, adapters (Figure 1) and message-oriented middleware (MOM), (Figure 2), and there are two techniques of data replication for implementing EAI (Figures 3 and 4). These techniques all perform the transformation (the T in ETL) of data to a common format to be used by all systems.
Adapters are specialized interfaces between diverse applications and allow those applications to directly communicate, in a form that is native to each application. Major application changes are typically not required, assuming that the application or adapter vendor has already created/provided the translation and interface for that application. The adapters perform the necessary translation to a common communications protocol that is understood by the adapter at each end.
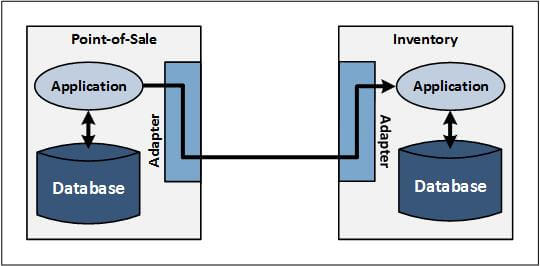
Figure 1 — EAI with Adapters
Figure 1 shows an example of application integration via adapters. A point-of-sale (POS) application communicates with an inventory application. Adapters on each system perform the necessary protocol translation between the applications native communication interfaces, enabling them to communicate without having to change programming.
Adapter services must be defined by a common interchange data format to which all systems conform for their inter-application communication. As a consequence, the use of adapters is often invasive to applications, and can add inefficiencies to the message path length for the various translations that occur. Each application involved in communicating with other applications must be modified to use the common data format for the messages that it sends and receives, or an adapter must be developed to the application’s existing interface. This problem is aggravated because knowledge is required of the proprietary formats used by the application vendors, information which many application vendors refuse to divulge. Consequently, adapter services can often only be implemented by the application vendor or in close cooperation with the application vendor.
Also, each application may need to be modified to know how to select events to send, to which systems to send these events, how to process events it receives from remote applications, and how to respond to requests from remote applications.
Adapters are highly specialized because each application requires its own adapter that connects to the adapter network and that translates its application interface and data formats into the common formats of the adapter network. The range of applications that participates in an EAI network interconnected with adapters is often limited, and customized or “home grown” applications often do not provide the services necessary to interface. These problems all served to inhibit the widespread use of adapters for application integration, particularly for highly customized or “home grown” applications.
Of course, some applications either provide an adapter themselves or rely on one of the adapter vendors to create one or more for them. For example, TIBCO Software, Inc. provides adapter technology for integrating many of the popular application packages.
Message-oriented middleware (MOM) provides a mechanism for asynchronously sending messages between applications. Messages are placed in queues and are sent to their destinations when the destinations are available. MOM is used to queue messages describing events and to send those messages to remote applications that take actions based on those events. MOM also provides the messaging facilities to send requests to other applications and to receive responses to those requests.
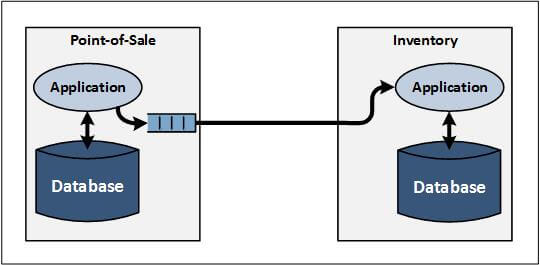
Figure 2 — EAI with Message-Oriented Middleware (MOM)
Figure 2 shows an example of application integration via MOM. The application examples used are the same as in Figure 1. In this case, the POS application puts messages into MOM queues. The MOM software then delivers the messages to other applications as configured (in this example, the inventory application).
However, the use of MOM in EAI suffers many of the same problems that adapters face. For one, MOM is invasive to the application, which can be architected into new applications. However, retrofitting the MOM calls into an existing application that requires access to the application source code, intimate knowledge of the application processing sequence, and extensive testing of the modified application. As with adapters, MOM requires that a common data format is established between all systems so that they can understand each other’s communications. Applications must be modified to conform to this format when they communicate with other applications. In addition, applications must be modified to know when to send messages and how to respond to messages from other applications, as well as how to recover/continue processing when the MOM interface fails or becomes unavailable.
MOM interconnects typically provide persistence of the messages being sent and returned, allowing for their asynchronous nature. Of course, in some cases, these messages are sent synchronously, with the sending application often blocking or waiting for the reply. In such architectures, loss of the interconnect infrastructure, even temporarily, often means the application itself is down, or at least severely impacted. This issue can be an important design consideration especially when the interconnect spans different systems or wide-area communications.
Data replication engines exchange data between systems at the database level. This data may take the form of events generated by one system for consumption by other systems, or it may take requests from one system to other systems and the responses to those requests. Figure 3 shows an example of application interoperability via data replication, known as data integration. The same application examples are used in Figure 1.
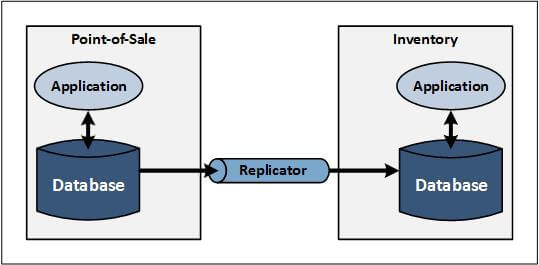
Figure 3 — EAI Intersystem Communication from Database to Database
In Figure 3, as the POS application updates its local database, the data replicator sends and applies these changes to the inventory database, where the data changes can be read by the inventory application and processed as appropriate. This approach is particularly useful for isolating target application processing from interconnection issues, since the receiving database is local to the target application environment. But, arguably, a more powerful approach is shown in Figure 4, where database changes in one database act as the real-time, event-driven feed into the other application. In order to interoperate with each other, applications may be integrated at the service layer or event layer.
Figure 4 shows an example of application interoperability via data replication, known as application integration. The same application examples are used in Figure 1. This example also involves the use of a data replicator, which delivers those changes directly to the inventory application, via an appropriate application interface, (instead of replicating the POS application data changes to the inventory database).
![]() Solution Brief: HPE Shadowbase Streams for Data and Application Integration
Solution Brief: HPE Shadowbase Streams for Data and Application Integration
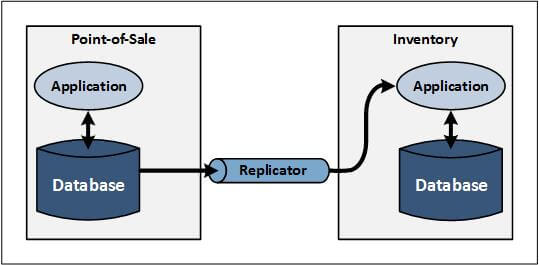
Figure 4 — EAI Intersystem Communication from Database to Application
With service level integration, special interfaces expose server system data or application services to external client applications. One way to accomplish this is via specially designed agents that reside on the server system. For instance, a database agent may provide access to the target database via ODBC, JDBC, OLE, XML, ADO.NET, or Representational State Transfer (REST).
Event level integration provides event driven integration services based on changes made to the source system’s database. Event level integration avoids the necessity of developing special agents or adapters for each application that is to be integrated. Rather, it monitors source application events in real-time and sends them immediately to the target application so that action can be taken on the event by the target.
Note that this description has used the term “system” rather than “application,” as was used in the descriptions for adapters and MOM. There is no integration with the data replication engine at the application level. Rather, replication works at the database level and occurs without any modification to the applications, which are typically unaware that replication is taking place. The only application modifications necessary are those required to implement new functions that make use of information from other systems (i.e., to take advantage of the availability of more information to more applications, enabling the rapid implementation of new business services).
A replication engine monitors changes to a system’s database and is driven by a change log, database triggers, or real-time change data capture (CDC). Based on rules incorporated into the replication engine, certain database changes found in the change log are sent to other systems in the application network. Alternatively, database triggers can pass critical changes to the replication engine for dissemination to other systems. These changes are either placed in tables in the target systems (Figures 3 and 4) or are otherwise delivered to the applications via an interprocess message, MOM, or queue and then may be used by applications to implement new functionality for the enterprise.
In addition to the advantage of noninvasiveness described above, data replication has other benefits than directly using adapters and MOM. For one, with adapters or MOM, the unavailability of the network or another system brings down the application because it no longer has access to the data that it needs. With replication, applications continue to function in the presence of network failures or external system outages by using the local copy of the application database.
Data replication also brings locality to the application, because the application has access to a local copy of the database. Performance is greatly enhanced, since it does not reach across the network for data. A common interchange data format is not required when using data replication engines, because the transferred data must be put into the target tables or target application’s request format according to specified formatting rules. The transformation of source data to target data is performed by the data replication engine according to transformation rules specified by the user and incorporated directly into the engine. Applications access the new data or receive the new requests just as they would access any data or request.
Another advantage of data replication engines is that security is significantly simplified. With adapters and MOM, every application is an interface and must be secured via encryption. Data replication engines present only a single interface that must be secured. Not only is the management of security simplified, but the number of points that may be attacked are also reduced.
Sophisticated data replication technologies, such as the HPE Shadowbase product portfolio, also provide mechanisms to replicate data between systems, as well as feed database changes directly to applications by sending events to client applications or servers via queues or client APIs, which publish data to applications that have subscribed to the data, or respond to poll queries from client applications. Since data replication avoids the application-specific problems associated with adapters and MOM, this mechanism has become the technique of choice for EAI.
EAI networks may either be mesh networks or hub networks. In a mesh network, every system is potentially connected to every other system. In a hub network, all systems communicate via a central hub that passes data to the target systems.
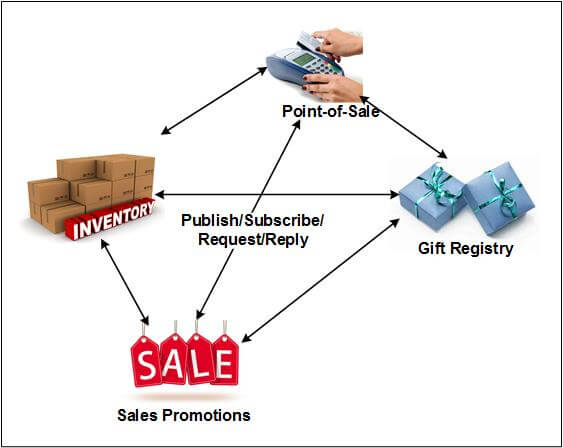
Figure 5 — EAI Mesh Network
Figure 5 shows an EAI mesh network, with bi-directional arrows representing the flow of information among POS, inventory, gift registry, and sales promotion applications. Each application can publish, subscribe, request, and reply to any other application from data events or requests that are being transferred across the network.
A problem with a mesh network is the number of possible connections. If there are n systems in the EAI network, there can potentially be n(n-1)/2 connections if all systems have to communicate with all other systems. If a new system is added to the network, n new connections may need to be established, one to each of the existing systems. This number of connections creates a network complexity that rapidly becomes unmanageable as the network grows.
A hub network eliminates this problem, as each system is connected only to the hub. Figure 6 shows an EAI hub network, with bi-directional arrows representing the flow of information from each application (POS, inventory, gift registry, and sales promotions) via the EAI hub, which routes each message to the appropriate target application.
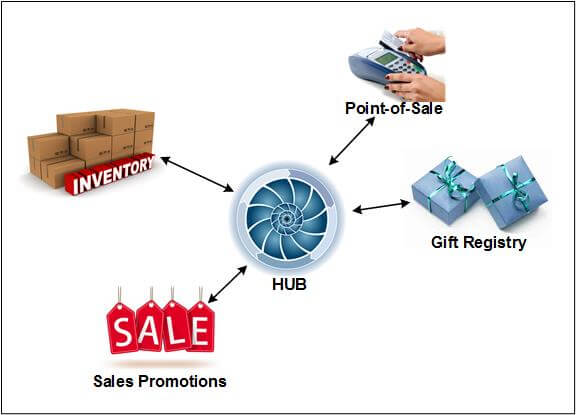
Figure 6 — EAI Hub Network
A hub receives messages from each system and routes each message to the appropriate target systems; however, it is a single point of failure, and a hub failure disrupts all functions that require data from other systems. Thus, all benefits of EAI are lost during a hub failure. Since these messages are functions that are tactical in nature, governing the real-time response of the enterprise to events as they happen, enterprise operations may be severely compromised following a hub failure. Consequently, the hub must be made redundant so that it is highly available.
Another difference between mesh and hub networks is that in a mesh network, every system must know the data format of every other system. Each system must be able to transform its data format into those of the other systems. But in a hub network the hub is responsible for data transformation. Each system needs to only know the data format expected by the hub.
Nevertheless, a mesh network does have the advantage of avoiding a potential bottleneck at the hub for information exchange, particularly if the systems are located close to one another but the hub is remote. If message latency is of paramount importance, or if a hub design can be overwhelmed with request arrival rate spikes, then a mesh design may be appropriate for at least some of the connections.
Using these techniques, EAI allows applications to integrate on a real-time basis as events occur and as databases are updated without having to wait hours, days, or weeks for data from a data warehouse. Consequently, EAI supports tactical decision-making very well, but it does not provide the historical data needed for strategic decision-making.
 Copy link to clipboard
Copy link to clipboard Email link
Email link Print
Print