Recently, a customer performing data validation identified some missing DR files and contacted Gravic for assistance. Upon review, the customer identified a misconfigured application as the issue.
Application Failover Did Not Include All of the Customer’s Applications
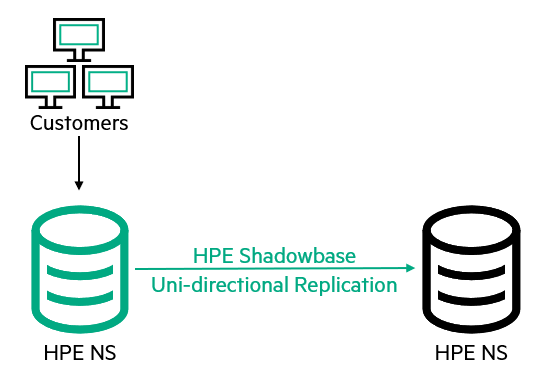
The customer replicates data in a uni-directional Active / Passive Post-Disaster Recovery configuration using two HPE NonStop systems.
Figure 1 – Uni-directional Active / Passive Post-Disaster Recovery
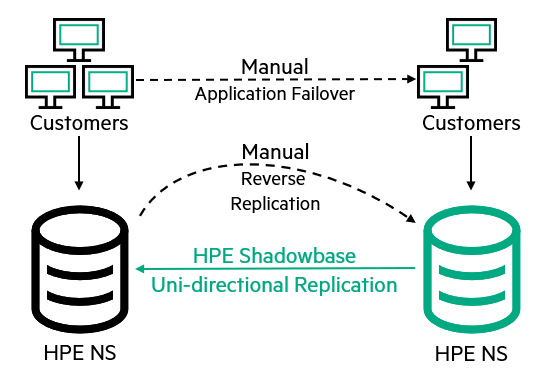
Every few months, the customer does failover testing. This architecture requires the customer to manually failover all of the required applications and switch replication in the opposite direction.
Figure 2 – Failover Testing
For some reason, one of the customer’s applications was not properly configured to failover and process transactions in the reverse direction.
Fixing Data Corruption
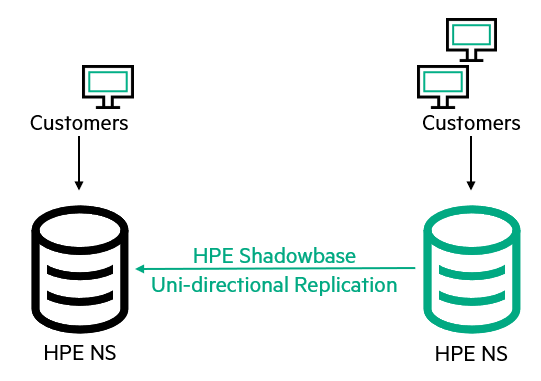
Upon further investigation and troubleshooting, when the application was running on the failover node, the customer noticed records changing on the old Production database. The data applied to the old Production database needed to be reapplied to the new Production database (on the failover node). In other words, the two nodes had switched roles, and one of the applications was pointing to the wrong database!
Figure 3 – Improper Failover Leads to Failover Faults
What Could Possibly Go Wrong?
The customer noticed and remediated this issue before serious data corruption occurred. They were lucky. Misconfigurations like this can happen in Active / Passive architectures and occur far more often than you may think.
Still, this use case highlights several important concepts:
The importance of Data Validation
— With frequent Shadowbase Compare runs, data discrepancies are flagged in a report, regardless of the source and target database polarities
The dangerous nature of Failover Faults
— Had the customer needed to failover to its backup, a portion of its data would be missing and have “disappeared” along with a “hung” application still making changes to the incorrect (former Production) database
The importance of Automated Failover and Recovery Detection
The customer utilized an Active / Passive replication architecture which requires a manual application switchover (reconnecting the app from \PROD -> \DR)
They did not have warnings enabled to flag when data was being changed “on the wrong database” (called Reverse Replication Cut-off in HPE Shadowbase)
The application switchover process was error-prone – the technologist performing the switchover tried their best but failed to include some of their applications in this process
This approach resulted in most of their apps successfully switching over, but there were still some apps that were incorrectly accessing the old Production system
If the customer had chosen a Shadowbase Sizzling-Hot-Takeover (SZT) architecture instead, the failover fault could have been detected based on user-defined conditions set in HPE Shadowbase
In addition, in an SZT environment, this failover process could have been tested and verified ahead of time to reduce and effectively eliminate the failover fault risks
Key Takeaways
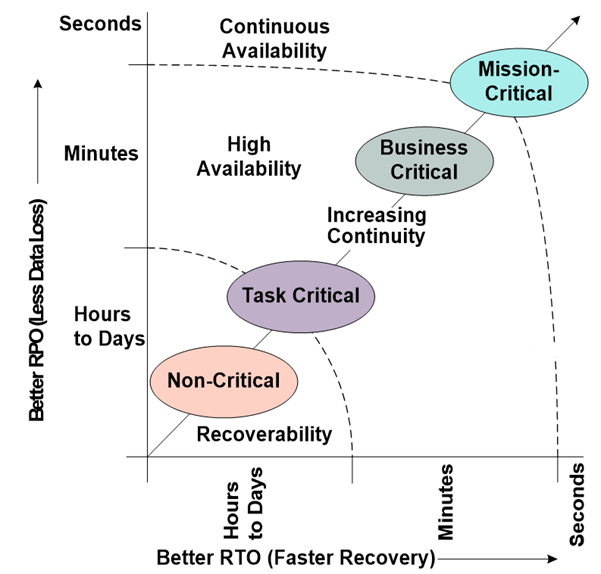
Business Continuity ContinuumThis use case highlights the importance of the Business Continuity Continuum (see Figure 4). It may seem difficult to implement Continuous Availability, but sometimes it is easier than you think. Other times, there are work-a-rounds and customizations that can be implemented for speed and efficiency. With a little help and a different perspective, what may seem like “a mountain to climb” may actually only be a hill.