Active/Active Systems for Master/Subordinate Peers Cell Phone Application
Share This!
 Copy link to clipboard
Copy link to clipboard Email link
Email link Print
Print
Situation
A major U.S. telecommunication (telco) provider offers provisioning and cellular infrastructure services to client companies, which provide their services through various applications to cell phone users.
Problem
- The telco needed to provide a continuously available, active/active application platform for its client companies.
- It needed to offer the HPE OpenCall INS cell phone application with considerable customizations to its client companies.
- One company had nine nodes in its architecture, and the system had to survive the loss of one or more of these nodes.
- The company’s nodes also needed to be geographically distributed to provide regional disaster tolerance (geographic redundancy).
Solution
- Use HPE Shadowbase bi-directional data replication in a multi-node, homogeneous, and fully bi-directional active/active architecture, designating “master” and “subordinate” nodes.
- The telco named this architecture the “N+1 Geographic Redundancy Option.”
- Note: data collisions can occur in this architecture. To resolve this issue, one node is selected as the “master” node, and the other nodes are “subordinate” nodes. If there is a data collision, the database’s update algorithm is “first to update the master wins.”
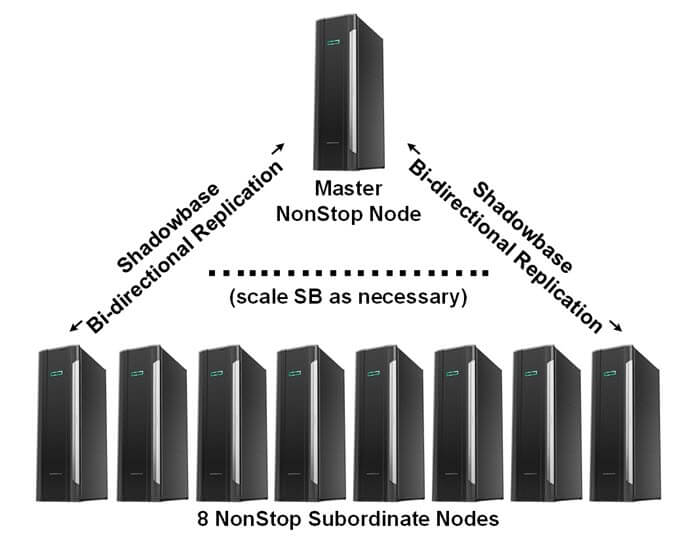
Figure 1 — Shadowbase for Scalable Homogeneous Active/Active Systems
Additional Master/Subordinate Architectural Notes
- Changes to the master node database are always directly replicated and applied to each of the child node databases (the master always wins).
- Changes to a subordinate node’s database are directly replicated to the master node, and if no data collision occurs, they are replicated back to all subordinate nodes and applied.
Outcomes
- Regional disaster tolerance: it allows the entire clustered solution to survive the loss of one or more nodes, depending upon the total number of nodes in the system. This greatly improved management’s confidence in the application’s durability, meaning its ability to survive faults.
- Load-balancing: each node uses a NonStop server that actively runs the application, processes any request, and is load-balanced (routed) to the least busy node.
- Data collision resolution: if a data collision has occurred at the master (because two or more subordinate nodes updated the same data item at the same time), only the first subordinate change is accepted; the other subordinate changes are logged and then discarded at the master, since they were not the first to update the master’s database.
- Hence, collisions are always resolved by the master node, which is the final adjudicator. The databases of all subordinate nodes may diverge, but will then converge to the contents of the master database.
- Scalability: there are as many subordinate nodes as are needed for the anticipated transaction volume. Additional subordinate nodes are provided to maintain full capacity in case one or more nodes fails. If the master node fails, one of the subordinate nodes is promoted to be the new master.
- Zero downtime migration capability: the telco uses the master/subordinate architecture to perform node upgrades without denying services to any of its users.
- When a subordinate node requires upgrading, it is removed from service. Further user requests are simply distributed among the remaining subordinate nodes.

 Achieving Century Uptimes with HPE Shadowbase Active/Active Technology
Achieving Century Uptimes with HPE Shadowbase Active/Active Technology