The Connection, March/April 2022
by Paden and Paul Holenstein
Business Continuity and Data Integration
Real-time data replication products, such as HPE Shadowbase software, are well known for their ability to facilitate IT service availability (Business Continuity) by replicating production data in real-time across multiple systems to create backup database copies. Should one system fail, current, consistent data is available on alternate systems which can take over processing, thereby maintaining service availability. But such products also provide another significant capability: a heterogeneous Data Distribution Fabric Backbone (DDFB), which facilitates data integration.
“We call data the new currency.” – Antonio Neri, HPE President and CEO1
Data is valuable. And the more current the data is, the more valuable it is. However, if this data is trapped or “siloed” in a single system, and not available to enable other real-time business intelligence processes, then its value is limited, and competitive opportunities are missed. To avoid these missed opportunities, companies need to liberate their trapped data in real-time, to integrate it with other data across the enterprise, and make it immediately available to other applications. This is the role of the DDFB, to take data from an operational mission-critical source database and make it immediately available to an analytics database (or wherever else the data may be needed).
A Data Distribution Fabric Backbone (DDFB)
HPE Shadowbase Data Integration (DI) provides a DDFB, enabling the integration of applications at the data level to create new and powerful functionality. It seamlessly copies selected data in real-time from a source database to a target database where it can be used by a target application or data analytics engine. As application changes are made to a source database they are immediately replicated to the target database to keep it synchronized with the source database. The DDFB is heterogeneous, data may be distributed between any source and target database and platform supported by HPE Shadowbase DI (HPE NonStop Enscribe, SQL/MX, SQL/MP, Oracle, SQL Server, Unix, Linux, Windows, etc.).
Upon delivery, the target application can then make use of this data, enabling the implementation of new event-driven services in real-time to enhance business competitiveness, to analyze data for new and valuable business insights, to increase revenue, and to satisfy regulatory requirements.
Data Transformation and Filtering
A key benefit of this DDFB model is that data replication is transparent to both the source and target applications. On the source side, the application simply makes its changes to the database as it normally would. Then, as part of the replication process, HPE Shadowbase software can transform (reformat) the data in order to meet the needs of the target application, which avoids the need to make any changes to the target application since it receives the data in exactly the right format. Data can also be filtered (cleansed) to eliminate any data that is of no interest to the target application, and/or sorted to deliver the changes in the desired order. The HPE Shadowbase Essentials Bundle also provides multiple tools2 to facilitate this data transformation and cleansing process:
- Shadowbase Map – SBMAP – a scripting “language” that can be used to inform Shadowbase software how to transform source data into target data formats. SBMAP is powerful, sophisticated, and extensible.
- Shadowbase DDL Utility – SBDDLUTL – a utility that reads an HPE Enscribe DDL record definition and produces a “flattened” (normalized) DDL structure along with an SQL CREATE TABLE statement for the selected target SQL environment. This capability simplifies the replication of unstructured Enscribe data into structured SQL databases.
- Shadowbase Create SQL/MP – SBCREATP – similar to the SBDDLUTL utility described above, this utility converts and maps SQL/MP table schema data structure definitions into target SQL equivalents. SBCREATP supports a variety of target SQL databases, including NonStop SQL/MX, Oracle, Microsoft SQL Server, IBM Db2®, Oracle MySQL, SAP HANA, and SAP Sybase. It is a key utility for customers performing Shadowbase DI replication from NonStop source SQL/MP tables out to SQL target tables. Without SBCREATP, the conversion work will have to be done by hand, a time-consuming and error-prone process.
- Shadowbase Create SQL/MX – SBCREATX – Similar to SBCREATP above, only for NonStop SQL/MX data sources (future product, contact Gravic for availability).
- User Exits – enable the inclusion and execution of customized user logic (program code) at various points in the Shadowbase replication stream and provide capabilities that are more complex than the scripting language. User Exits are extremely flexible, enabling almost any kind of data transformation, and can also perform specific field/column-level encryption and data tokenization.
- DBS Mapping – a scripting “language” to transform data on target databases. E.g. drop all events for a target table; drop columns and/or certain events for a target table; convert updates to inserts; concatenate (text) columns; and reformat and convert/replace characters.
Data Integration Case Studies
With the explosion of data creation now upon us, it is clear that companies who can effectively manage their data to extract its value to create new solutions can achieve competitive advantages. Using data integration, this includes, for example, feeding data lakes and decision support systems (DSS), data warehousing, real-time fraud detection, and fare modeling.
Let’s review a few real-world examples illustrating this advantage, new opportunities, and added value that HPE Shadowbase Data Integration can bring to an enterprise.
Offloading Query Activity from the Host and Enabling OLAP Processing
A large European steel tube manufacturer runs its online shop floor operations on an HPE NonStop Server. To exploit the currency and value of this online data, the manufacturer used to periodically generate reports on Linux Servers using a customized application and connectivity tool that remotely queries the online NonStop Enscribe database and returns the results.
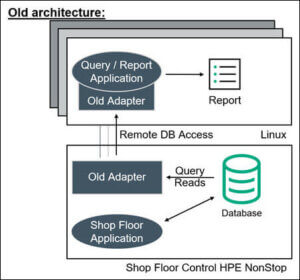
Figure 1 – Shop Floor Operations with the Old Adapter
With this original architecture (Figure 1), every time a Linux query/report was run, processing on the NonStop Server was required, and as query activity increased, this workload started to significantly impact online shop floor processing. This impact was compounded due to the high volume of data transformation and cleansing required for converting the NonStop’s Enscribe data into a usable format for the reports3. Periodically, the company needed to suspend the execution of these reports due to these production impacts. In addition, the remote connectivity architecture was not very robust or scalable, and was also susceptible to network failures, timeouts, and slowdowns when operating at full capacity.
Since the data adapter used was nonstandard, the manufacturer could not access the data using standard ODBC4 and OLAP5 tools to take advantage of new analytical techniques (such as DSS6). Furthermore, the company had a new requirement to share the OLAP analysis with the online NonStop applications in order to optimize shop floor control, which was completely impossible with the original solution. Therefore, a new architecture was required to address these issues and meet the new requirements.
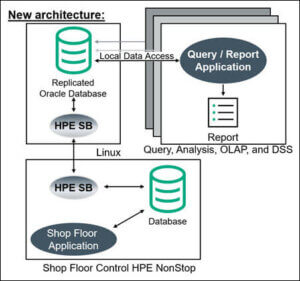
Figure 2 – Offloading Query Activity from the Host and Enabling OLAP
The manufacturer completely rearchitected its Linux-based querying/reporting application (Figure 2). Rather than remotely querying the NonStop Enscribe data each time a report is run, the data is replicated by Shadowbase software in real-time from the Enscribe database to a relational copy of that database hosted on a Linux system. This architectural change only requires sending the data across the network once (when it is changed), instead of every time a query/report is run, significantly decreasing the overhead on the production system.
The raw Enscribe data is non-normalized, and full of arrays, redefines, and data types that do not have a matching SQL data type. As part of the replication process, the non-relational Enscribe data is transformed and cleansed by Shadowbase technology into a relational format, and written to an Oracle RAC database. This architectural change only requires cleansing or normalizing the data once (when it is changed), rather than every time a query/report is run.
Since the data is now local to the Linux Servers and presented in standard relational format, it is possible to use standardized SQL data query and analysis tools. In addition, Shadowbase software allows the manufacturer to reverse-replicate the OLAP results and share them with the NonStop applications to better optimize the shop floor manufacturing process.
Optimizing Insurance Claims Processing
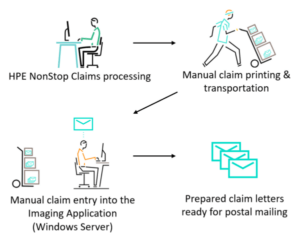
Figure 3 – Old Insurance Claims Process
As shown in Figure 3, an insurance company provided insurance claims processing for its client companies. It used an HPE NonStop Server to perform processing functions required for each claim and an imaging application to prepare form letters that were the primary interaction with the clients’ customers. The imaging application ran on a Windows server and utilized a SQL database. As claims were made, they entered the NonStop claims processing system, then any pertinent information was sent manually to the imaging application on the Windows server. The system created and printed the appropriate letters, which were sent to the customers. The imaging application then returned a completion notification to the claims system, and informed it that the forms were generated.
This manual process was error prone, duplicates effort, and is time consuming. Also, the company was unable to automatically and quickly meet its clients’ needs when checking claim status and verifying claim information.
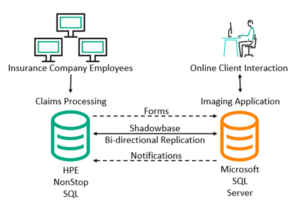
Figure 4 – Optimizing Insurance Claims Processing
The company wanted a faster and more efficient system that would not only reduce letter production time but also the number of personnel involved. Shadowbase DI was selected to help automate this process.
In the new application architecture, claims are entered into an HPE NonStop application for processing. Then, pertinent form information from the claims system is sent to a Windows SQL server imaging application via Shadowbase heterogeneous data integration. The imaging application then creates and prints the appropriate forms, which the company mails to the insurance customer, and sends a completion notification via Shadowbase replication back to the claims system, informing it that the forms were generated. This architecture reduces user data entry redundancy and errors as well as increases the speed of claim status updates, enabling much faster processing of claims, all at a reduced cost.
Rail Occupancy and Fare Modeling
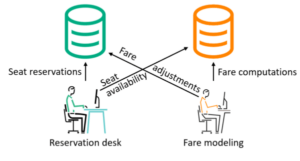
Figure 5 – Manual Fare Pricing
A European railroad needed to monitor its seat reservation activity in order to create a fare model reflecting the usage of the rail line. The fare modeling was a computationally intensive application running on a Solaris system with an Oracle database. Fare modeling involved manually looking at seat reservations, generating reports and statistics, and was prone to human error and misinterpreting data (Figure 5).
In the new architecture (Figure 6), an HPE NonStop Server hosts a ticketing and seat reservation application. As tickets are sold, the reservation information is replicated from the NonStop SQL database to an Oracle database on a Solaris system.
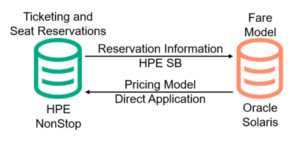
Figure 6 – Data Integration for Automated Rail Occupancy and Fare Modeling
There, the fare modeling applications track reservation activity and make decisions concerning future fares. The fare modeling application sends back the updated pricing information to the NonStop Server for ticket availability and pricing updates and then logs consumer demand so that the company can attain price equilibrium for optimum profits.
Both applications and databases are updated in real-time: Shadowbase heterogeneous data integration updates the Oracle target with the reservation information, and the updated pricing model information is supplied through a direct application link back to the NonStop. The railroad can now monitor ridership traffic and automatically modify its fare model to maximize profits in real-time.
Prescription Drug Fraud Monitoring

Figure 7 – Prescription Fraud
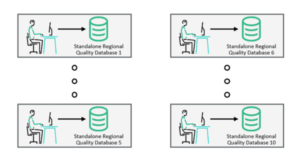
A national healthcare agency processes all prescription insurance claims for the country’s healthcare market with a set of applications on HPE NonStop systems. The agency is facing exponential growth in the number of prescriptions due to an aging population along with prescription fraud and abuse. A new integrated system was needed to allow filling valid prescriptions while identifying and flagging fraudulent prescription and reimbursement requests (Figure 7). Due to privacy laws, various jurisdictions maintained data silos, which made it difficult to consolidate data for analysis.
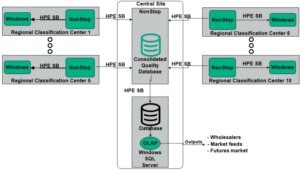
Shadowbase DI was used to integrate the claims processing application with a prescription fraud Decision Support System (Figure 8).
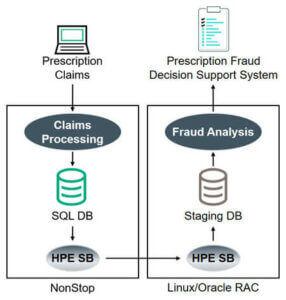
Figure 8 – Prescription Drug Fraud Monitoring
This new architecture halts fulfillment of suspicious claims in real-time across all jurisdictions, and provides perpetrator information to law enforcement for monitoring, investigating, and prosecuting fraudulent claims activity. It also stems fraudulent reimbursements to pharmacies, doctors, and patients, saving the healthcare system substantial costs.